
The Hadoop Ecosystem
6 September 2017 (14-21h)
Location: Parker Hotel (Diegem)
Presented in English by Geert Van Landeghem
Price: 640 EUR (excl. 21% VAT)

This event is history, please check out the List of Upcoming Seminars, or send us an email
Check out our related in-house workshops:
- Google BigQuery in Practice (INHOUSE WORKSHOP - On Request)
- Apache Spark Hands-On Training (In-Company) (INHOUSE WORKSHOP - On Request)
- Het Logisch Datawarehouse - Architectuur, Ontwerp en Technologie (INHOUSE WORKSHOP - On Request)
- Business Intelligence en Datawarehousing Fundamentals (INHOUSE WORKSHOP - On Request)
- The Hadoop Ecosystem (INHOUSE WORKSHOP - On Request)
- Big Data Oplossingen voor BI (INHOUSE WORKSHOP - On Request)
- Data Vault in a Day (INHOUSE WORKSHOP - On Request)
Learning Objectives
Why should you attend this seminar about the Hadoop ecosystem ?
![]() During this seminar, you will get real answers to these and other questions:
During this seminar, you will get real answers to these and other questions:
- What is Hadoop and how does it fit in the big data (r)evolution ?
- Which components are part of the Hadoop ecosystem ?
- How do you import enterprise data into Hadoop?
- What are the possibilities to store data on Hadoop?
- How do you model data on Hadoop?
- How do you maintain different versions of data?
- How do you process data stored on Hadoop?
- How do you integrate Hadoop in your enterprise?
- How do you keep an Hadoop cluster up and running?
- Which use cases can be implemented using Hadoop?
Why do we organize this seminar ?
The rise of the Internet, social media and mobile technologies, and in the very near future the Internet of Things (IoT) ensures that our data footprint is growing fast. Companies like Google and Facebook were quickly confronted with massive data sets, which led to a new way of thinking about data.
The last 10 years, Hadoop provides an open source solution based on the same technology used within Google. It allows you to store and analyze massive amounts of data to create new insights.
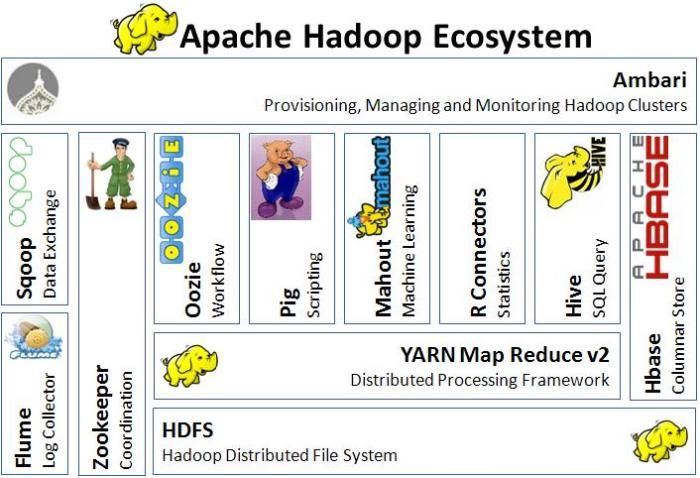
With this seminar, we want to give everyone the opportunity to get acquainted with this revolutionary technology and the concepts behind it. You will get an overview of:
- HDFS, HBase and Hive, the most important storage technologies
- MapReduce and Spark, the most important processing frameworks
- YARN and Mesos, the most important resource managers
- Sqoop, Flume and Kafka as the most important integration tools
- Solr and ElasticSearch as the most important indexing and search engines
Most of these technologies are covered during this one-day seminar, as well as a lot more:
Who should attend this seminar ?
This seminar is aimed at everyone who wants to use big data technology, and therefore needs to understand the components of the Hadoop ecosystem and the concepts behind them. This seminar is presented in English.
Full Programme
- HDFS
- HBase
- Hive
- The "Hadoop Data Lake"
- MapReduce
- Apache Spark
- Sqoop
- Flume
- Kafka
Most of these technologies are covered during this one-day seminar, as well as a lot more:
- YARN and Mesos
- Cloudera Manager
- Ambari
Speakers
Geert Van Landeghem is a Big Data consultant with 25 years of experience working for companies across industries. He worked on his first big data project in 2011, and is still consulting companies on how to adopt big data within their organisation.
He has worked as the Head of BI for a gambling company in Belgium, where he led a team of 8 people. He is an Apache Spark Certified Developer since November 2014, and has worked as an instructor for IBM and Datacrunchers, where he teaches Hadoop and Spark-related courses.
He is currently examining how Artificial Intelligence can be used for business use cases and as such followed the first IBM Watson and O'Reilly AI conferences abroad.
Questions about this ? Interested but you can't attend ? Send us an email !